
Revisión Sistemática: Guía básica de cribado
En esta entrada recojo una guía básica de recomendaciones, en base a mi conocimiento y experiencia, para la realización del cribado de estudios a incluir en una revisión sistemática.
La fase de cribado de una revisión sistemática es una de las más importantes de este tipo de estudios. Dependiendo de los resultados de nuestras búsquedas, el cribado puede llevar demasiado tiempo, no obstante, existen algunas estrategias para optimizar el tiempo de realización de dicha fase, así como la calidad metodológica de la misma. En esta entrada explicaré como suelo proceder a la hora de planificar y realizar dicha fase en una revisión sistemática.
Esquema de realización del cribado
Antes de proceder con la explicación de las distintas fases del cribado de una revisión sistemática, mostraré aquí un esquema (que será el que seguiré) de los pasos a seguir:
- Selección de las aplicaciones a utilizar para el cribado.
- Importación de las búsquedas.
- Detección y eliminación de duplicados.
- Criterios de inclusión/exclusión.
- Palabras clave para facilitar el cribado.
- Pilotaje previo: análisis de concordancia entre revisores.
- Cribado de título y resumen.
- Resolución de conflictos.
- Organización del sistema de criterios de exclusión.
- Cribado de texto completo.
- Resolución de conflictos.
Aplicaciones para el cribado
Actualmente utilizo dos aplicaciones web que pueden optimizar mucho el tiempo de realización de la fase de cribado, Covidence y Rayyan. En la siguiente tabla muestro una comparativa general de ambas con respecto a varias funciones.
$$\begin{array} {| ccc |} \hline \textbf {Rayyan} & \textbf {Covidence} \\ \hline Gratuito & Pago \ (> 500 \ articulos) \\ \hline Duplicados \ a \ mano & Duplicados \ automatico \\ \hline Multiples \ revisores & Solo \ dos \ revisores \ (gratis) \\ \hline No \ ambos \ cribados & Ambos \ cribados \\ \hline \end{array}$$
A pesar de que el precio por usar Covidence de manera íntegra es elevado, la parte gratuita de la misma es bastante útil en la fase de cribado, como explicaré más adelante. Además de utilizar Covidence y Rayyan, también recomiendo utilizar la aplicación de escritorio de Mendeley y Microsoft Excel. A continuación muestro un resumen de la finalidad con la que utilizar cada una de dichas aplicaciones:
- Mendeley:
- Importación de artículos.
- Covidence:
- Detección y eliminación de duplicados.
- Rayyan:
- Detección y eliminación de duplicados.
- Pilotaje.
- Cribado de título y resumen.
- Microsoft Excel:
- Cribado de texto completo.
Importación de búsquedas
Antes de proceder al cribado de los artículos, es necesario importar los archivos extraídos de las distintas bases de datos que contienen nuestras búsquedas. No todas las bases de datos permiten exportar las búsquedas realizadas en los mismos formatos y no todas las aplicaciones permiten importar archivos en los mismos formatos. En la siguiente tabla muestro los tipos de archivos que permiten importar las tres aplicaciones que suelo utilizar en una revisión sistemática.
$$\begin{array} {| ccc |} \hline \textbf {Rayyan} & \textbf {Covidence} & \textbf {Mendeley} \\ \hline EndNote \ (.enw) & EndNote \ XML \ (.xml) & EndNote \ XML \ (.xml) \\ Refman/RIS \ (.ris) & RIS \ (.ris) & BibTeX \ (.bib) \\ BibTeX \ (.bib) && RIS \ (.ris) \\ CSV \ (.csv) & & Zotero \ Library \ (zotero.sqlite) \\ Pubmed \ XML \ (.xml) & & \\ Nuevo \ Pubmed \ (.nbib) & & \\ Web \ of \ Science/CIW \ (.ciw) & & \\ \hline \end{array}$$
Como puede apreciarse, Covidence está muy limitado en cuanto al tipo de archivos que permite importar y este es el motivo de que haya añadido Mendeley al listado de aplicaciones a utilizar en la fase de cribado. Todas las bases de datos que suelen consultarse en revisiones sistemáticas en Fisioterapia permiten exportar las búsquedas en alguno de los formatos permitidos por Mendeley. De este modo, si realizamos una búsqueda en una base de datos que no permite exportar en un formato aceptado por Covidence, lo que yo suelo hacer es importar dichas búsquedas a Mendeley, para después exportar esos artículos con formato .ris, una función que Mendeley permite, pudiendo finalmente importar dichas búsquedas en Covidence. Es indispensable poder importar todas las búsquedas en Covidence, ya que esta es la aplicación a utilizar en la primera fase de la detección y eliminación de duplicados.
Detección y eliminación de duplicados
Es importante reportar las herramientas utilizadas para proceder con la detección y eliminación de duplicados, entre otras cosas por un motivo de transparencia y de facilitación de reproducibilidad de la metodología empleada para el cribado, de acuerdo a las recomendaciones de la declaración PRISMA de reporte de las búsquedas en una revisión sistemática.
A pesar de que la aplicación web Covidence es de pago, una de sus funcionalidades gratuitas es de gran ayuda. Como ya he comentado, Covidence solo permite cribar de manera gratuita hasta un máximo de 500 artículos. Sin embargo, aunque no podamos cribar más de 500, si podemos importar más de 500, de hecho, podemos importar el número que necesitemos de artículos y proceder a la detección y eliminación de duplicados con dicha aplicación. Este primer paso es muy relevante, ya que a diferencia de Rayyan, Covidence si elimina los duplicados de manera automática. Una vez realizado este primer paso, procederemos a exportar los artículos restantes de Covidence para importarlos en Rayyan, donde proseguiremos con esta fase.
A pesar de que Covidence detecta y elimina la gran mayoría de duplicados, aun se deja algunos que detectará Rayyan. La desventaja de Rayyan es que, aunque detecta los duplicados de manera automática, no los elimina. Rayyan detectará posibles duplicados de acuerdo al porcentaje de concordancia de palabras en los distintos campos de importación de los artículos y luego tendremos que ir revisando uno a uno los casos de posible duplicado y decidir si existe o no duplicación y eliminar el artículo que no nos interese.
Por mi experiencia con grandes importaciones de artículos (6000 a 9000), el paso de Covidence lo considero indispensable, pues la tarea de eliminación manual de duplicados en Rayyan con cantidades de 1000-2000 duplicados, llevará demasiado tiempo sin existir necesidad para ello. Normalmente, con cantidades altas de resultados en las búsquedas como las referidas al inicio de este párrafo, una vez eliminamos duplicados en Covidence, los que suelen detectarse en Rayyan son pocos, entre 100-300 en las revisiones que he llevado a cabo, un número asequible para resolver manualmente en esta aplicación.
Por último, cabe destacar que, a pesar de usar dos aplicaciones, aún pueden quedar duplicados sin detectar que se deberán eliminar posteriormente en las fases respectivas de cribado de título-resumen o texto completo.
Criterios de inclusión y exclusión
El establecimiento de unos criterios de inclusión y exclusión claros resulta obvio para una buena calidad de la fase de cribado y a nivel general, para una buena calidad de la revisión sistemática.
El establecimiento de los criterios de inclusión y exclusión tiene, a mi modo de ver, dos partes: la parte explícita que se reportará en el manuscrito final y la parte no explícita que no se reportará, pero que es de suma importancia durante el proceso de cribado. Explicaré este punto con un ejemplo práctico de una revisión que estoy actualmente realizando, donde un criterio de inclusión explicito es: “Medir la cinemática escapular durante la elevación/descenso del brazo con sistemas de medición 3D que no sean de superficie”.
Este sería el criterio explícito, tal cual se reportará en el manuscrito de la publicación. Por otro lado, tendríamos la parte no explícita del criterio, que sería en parte la siguiente:
- Sistemas optoelectrónicos no se incluyen (son de superficie).
- Sistema VICON no se incluye (es de superficie).
- Sistemas basados en sensores con cámaras infrarrojos no se incluyen (son de superficie).
- Sistemas elecromagnéticos pueden ser de superficie o acoplados a pins insertados en hueso. Los primeros no se incluyen y los segundos sí.
- En caso de que no se reporte el tipo de sistema electromagnético en título/resumen, se incluye el estudio y en la fase de texto completo se evaluará si es de superficie o con pins insertados en hueso para ver si finalmente se incluye el artículo o no.
- Sistemas de fluoroscopia y radiografía de incluyen (no son de superficie).
Estos son algunos de los puntos no explícitos que acompañan a ese criterio explícito. El problema de no tener claros estos puntos y no detallarlos adecuadamente en las instrucciones para los revisores que realizarán el cribado, es que puede ser que se dejen estudios fuera que podrían haberse incluido o viceversa. En el segundo caso tiene solución ya que los podremos excluir finalmente cuando el IP tenga acceso al listado final de artículos incluidos. Sin embargo, en el primer caso (excluir estudios susceptibles de haber sido incluido), no podremos detectar que esto ha sucedido ni solventarlo.
El investigador encargado del establecimiento de los criterios de inclusión/exclusión debe valorar que los revisores que realizarán el cribado puede que no tengan el mismo conocimiento que él/ella (ej. Puede que los revisores no sepan que un sistema optoelectrónico es de superficie), y que es su obligación detallar al máximo posible los distintos criterios, así como posibles situaciones donde surja duda (como el caso de los sensores electromagnéticos donde no se reporta si son de superficie o no), para que los revisores tenga claro qué decisiones tomar y no se vea afectada la calidad de la fase de cribado.
Mi recomendación es elaborar una lista detallada de los criterios de inclusión/exclusión explícitos y todos sus componentes no explícitos en un Word y, previo comienzo al cribado, organizar una reunión con los distintos revisores que intervendrán en la misma para aclarar cualquier posible duda al respecto de manera previa.
Palabras clave para facilitar el cribado
Una de las utilidades que presenta Rayyan y que mejorará no solo el tiempo de realización del cribado de título y resumen, sino también posiblemente su calidad, es la presencia de palabras clave destacadas.
Cuando importamos un listado de artículos en Rayyan, la aplicación elabora de manera automática un listado de palabras clave destacadas de inclusión y exclusión, las cuales recomiendo encarecidamente eliminar para elaborar nuestra lista propia, ya que el listado facilitado por Rayyan normalmente no se adecua a los objetivos de nuestra revisión.


Las palabras claves de inclusión aparecerán destacadas en verde y las de exclusión en rojo, facilitando visualmente el cribado. Hay veces en las que la presencia de una palabra determinada en el título de un estudio, por ejemplo «systematic review» es motivo suficiente para su exclusión. El disponer de un listado de palabras de exclusión facilita detectar estos artículos de manera rápida visualmente y por tanto optimizar el tiempo necesario para esta fase de cribado. Del mismo modo, el disponer de palabras resaltadas en el resumen puede facilitar la localización de la información relevante para decidir si se debe incluir o excluir dicho artículo durante esta fase de cribado, siendo de especial utilidad en la detección de las partes no explícitas de los criterios de inclusión y exclusión.
Pilotaje previo: análisis de concordancia entre revisores
La fase de pilotaje previo es una de las más importantes con respecto al cribado en una revisión sistemática, siendo actualmente recomendada por la Colaboración Cochrane. El objetivo de esta fase es evaluar si los revisores que realizarán el cribado han comprendido adecuadamente los criterios de inclusión y exclusión, antes de proceder al cribado de todos los estudios encontrados con la estrategia de búsqueda.
Si los revisores no tienen claros los criterios de inclusión y exclusión, pueden originarse muchas discrepancias entre ellos, que deberán ser resueltas por un tercer revisor. Sin embargo, aunque podríamos pensar que este es el motivo principal de realizar el pilotaje previo, existe otro motivo aún más importante. Del mismo modo que una falta de comprensión de los criterios puede hacer que un revisor incluya un estudio y otro revisor lo excluya, también puede producir que dos revisores excluyan un artículo que fuera susceptible de haber sido incluido en la revisión. En el primer caso, disponemos de otra fase que es la resolución de conflictos, donde podrá solventarse en parte ese problema. Sin embargo, si dos revisores deciden excluir un artículo que debería haberse incluido, habremos perdido ese estudio en esta fase de cribado y no tendremos forma de saber que hemos errado ni de solucionar el problema posteriormente. Este es el motivo principal por el cual es importante hacer el pilotaje previo, para prevenir que esto suceda.
Cuando realizamos la búsqueda en las distintas bases de datos podemos encontrarnos en dos situaciones distintas, según la cual recomiendo proceder de una u otra forma con respecto al pilotaje previo:
- Número pequeño de artículos encontrados (suelo usar un punto de corte de < 500 estudios tras eliminar duplicados): No realizar pilotaje previo.
- Número elevado de artículos encontrados: Pilotaje previo con 200-300 artículos.
Número pequeño de artículos
Cuando el número total de artículos a cribar en la fase de título y resumen no es muy elevado (< 500), se puede optar por no realizar un pilotaje previo. El motivo por el cual recomiendo esto es porque, desde mi punto de vista, el número de artículos que podremos seleccionar para realizar el pilotaje será demasiado pequeño y esto puede dar lugar a resultados extremos en el análisis de concordancia, sin que podamos asegurarnos que dicha concordancia se mantenga en el resto del cribado. Es por ello que, en estos casos, considero más útil realizar el cribado directamente y realizar el análisis de concordancia con el total de artículos incluidos. En caso de que dicho análisis no salga óptimo, se llevaría a cabo una reunión de resolución de dudas con respecto a los criterios de inclusión y exclusión para volver a proceder a cribar todos los artículos nuevamente, antes de pasar a la fase de resolución de conflictos.
Número elevado de artículos
En este caso si considero adecuada la realización del pilotaje. La propuesta que muestro de número de artículos a utilizar es debida a que, según mi conocimiento, ese número de estudios parece ser suficiente para asegurar niveles adecuados de precisión en la estimación de distintos coeficientes de fiabilidad de variables categóricas, como el Kappa de Cohen o el AC1 de Gwet, que son las dos propuestas que recomiendo utilizar.
Lo ideal sería poder realizar un muestreo aleatorio de los estudios a utilizar para realizar el cribado, pero esto por experiencia, requiere de demasiado trabajo. El motivo de llevar a cabo ese muestreo ideal sería obtener una muestra representativa de estudios con respecto al total de estudios que posteriormente se cribarán en la fase de título y resumen. A pesar de que considero esta aleatorización, a nivel práctico no viable, si que podemos tener en cuenta alguna consideración para evitar sesgar el pilotaje en cierta medida. Recomiendo encarecidamente evitar:
- Seleccionar estudios de una sola base de datos (mínimo 2).
- Seleccionar solo estudios de una franja temporal (ej. solo estudios antiguos entre 1990 y 2000, cuando nuestra muestra de estudios a cribar para la revisión incluye artículos de 1990 hasta el año 2020).
El primer punto puede no meter muchos sesgos, pero el segundo si es importante evitarlo. Por ejemplo, puede ser que estemos realizando una revisión sobre la efectividad de una intervención que antiguamente no se utilizase, de forma que si en el pilotaje incluimos solo estudios muy antiguos, puede ser que apenas salgan estudios de inclusión, de manera que solo podríamos evaluar si hay buena concordancia con los criterios de exclusión, pero no con los de inclusión, de forma que el pilotaje no sería útil.
El pilotaje deberá realizarse igual que se realizará el cribado posterior, es decir, utilizando la misma aplicación y el mismo listado de palabras clave destacadas (si se deciden usar).
Interpretación del análisis de concordancia
La fase de pilotaje presenta una característica a tener en cuenta para la interpretación de los análisis estadísticos de concordancia, el efecto de la elevada prevalencia de los estudios a excluir. Normalmente, la mayor parte de estudios de una revisión sistemática serán excluidos durante el cribado y este desequilibrio entre los SI y los NO tiene repercusiones en estadísticos como el Kappa de Cohen, pudiendo darse el caso de un alto grado de concordancia entre los examinadores con un valor no tan alto del Kappa de Cohen. Existen dos opciones:
- Interpretar el valor del Kappa de Cohen junto con los índices de prevalencia y sesgos, así como el Kappa ajustado para la prevalencia y sesgos (PABAK).
- Utilizar el coeficiente AC1 de Gwet, que es más robusto ante ese efecto de la prevalencia.
En cualquiera de los casos, recomiendo valores superiores a 0.70-0.80 del PABAK o AC1 de Gwet para poder asumir una buena concordancia entre los examinadores. No obstante, también debe evaluarse otro aspecto, el número total de estudios incluidos en el cribado (de acuerdo de inclusión). Por ejemplo, imaginemos un caso de un pilotaje de 200 artículos donde existe un 10% de discrepancias (20 artículos con discrepancias), es decir un porcentaje pequeño, en dos escenarios distintos:
$$Escenario \ 1= \begin{bmatrix} & Incluido & Excluido\\Incluido & 2 & 10 \\Excluido & 10 & 178\end{bmatrix}, \ AC1 = 0.89$$
$$Escenario \ 2= \begin{bmatrix} & Incluido & Excluido\\Incluido & 20 & 10 \\Excluido & 10 & 160\end{bmatrix}, \ AC1 = 0.87$$
En ambos casos simulados hay el mismo porcentaje de discrepancias y tenemos un valor similar del coeficiente AC1 de Gwet, sin embargo, las dos situaciones son muy diferentes en cuanto a interpretación. En el primer caso, solamente hay acuerdo de inclusión en dos estudios. Este numero es especialmente pequeño y en estos casos la decisión que suelo tomar es concluir que no ha habido una concordancia suficiente como para poder proceder con el cribado. En el segundo caso, sin embargo, mi actuación sería proceder con el cribado, asumiendo un porcentaje aceptable de concordancia entre los revisores.
Análisis y aclaración de conflictos
Cuando se realiza la fase de pilotaje existen dos posibles resultados, que concluyamos que hay un acuerdo aceptable entre los revisores o que no. En ambos casos se procederá con el análisis y aclaración de los conflictos, sin embargo, si concluimos que no ha habido un acuerdo adecuado, el siguiente paso sería repetir el pilotaje con una muestra nueva de estudios, mientras que si hemos concluido que el acuerdo era aceptable, entonces se procederá con la fase de cribado de título y resumen.
Durante la fase de análisis y aclaración de conflictos, el investigador principal deberá revisar los artículos en los que han habido las discrepancias a fin de dilucidar los posibles malentendidos con los criterios de inclusión y/o exclusión que han llevado a tales discrepancias. Posteriormente, deberá elaborar un documento word con las aclaraciones pertinentes, pero sin nombrar estudios concretos, es decir, no se puede decir «el estudio X debería haberse incluido por este motivo». Simplemente deberán recogerse las aclaraciones con respecto a los criterios de inclusión/exclusión que el investigador principal consideré pertinentes con respecto a las discrepancias observadas.
Cribado de título y resumen
Durante esta fase, como su propio nombre indica, se cribarán los artículos por título y resumen igual que se hizo en la fase de pilotaje, salvo que aquí se cribarán ya todos los estudios susceptibles de ser incluidos en la revisión sistemática.
La totalidad de esta fase recomiendo realizarla en Rayyan, ya que su realización en Excel incluso con un número pequeño de artículos, requerirá de más tiempo del necesario. Un aspecto que merece la pena ser remarcado con respecto a esta fase del cribado es la primacía de la sensibilidad sobre la especificidad.
Durante esta fase, es recomendable que en caso de duda sobre si incluir o no un determinado estudio, por falta de información, se incluya. Supone un mayor problema excluir un estudio que realmente debería haberse incluido en la revisión, que decidir incluir en la fase de titulo y resumen un estudio que no deba incluirse. En el segundo caso, con el posterior cribado de texto completo, donde disponemos de más información, se podrá discernir si realmente el estudio ha de ser incluido o no, por lo que no sería un problema. Sin embargo, como ya he comentado, si ambos revisores excluyen un artículo que debiera incluirse, no tenemos forma de detectar este suceso ni tomar medidas para remediarlo.
Por último, cabe destacar que en esta fase han de incluirse nuevamente también todos los artículos utilizados para el pilotaje previo, es decir, dichos artículos se cribarán nuevamente a pesar de haberse utilizado para la fase de pilotaje.
Resolución de conflictos
La fase de resolución de conflictos de título y resumen puede realizarse en Rayyan, aunque la aplicación no permite como tal “resolver los conflictos”, pero podemos organizar esta fase de manera manual. Rayyan dispone de un botón de enmascaramiento que podemos apagar, de tal manera que al acceder a la revisión se puedan observar las decisiones de ambos revisores y seleccionar un apartado donde solo se incluyen los artículos con discrepancias.
El primer paso para planificar esta fase es desactivar el botón de enmascaramiento, acceder al apartado de discrepancias y exportar dichos estudios. Después deberemos crear una nueva revisión en Rayyan, donde importaremos solo los estudios con discrepancias, para que el tercer evaluador encargado de resolverlas cribe dichos estudios sin conocimiento de las decisiones de los revisores previos.
Tendremos por tanto dos archivos que exportar en formato .csv, uno de la revisión original con los artículos que ambos revisores decidieron incluir y otro de la revisión creada para resolver las discrepancias con los artículos que el tercer revisor decidió incluir. Estos serán los artículos que se cribarán en la fase posterior de texto completo.
Organización del sistema de criterios de exclusión
A diferencia de la fase de cribado de título y resumen, donde no es necesario reportar los motivos de exclusión de acuerdo a las recomendaciones de la Cochrane, en la fase de cribado a texto completo si es necesario hacerlo. Es por ello que, el primer paso para planificar esta fase será la organización de dichos criterios de exclusión.
Debido a que en esta fase han de reportarse los motivos concretos por los que se excluye cada artículo, esto ha de tenerse también en cuenta a la hora de evaluar posteriormente las discrepancias, ya que puede ser que dos revisores decidan excluir un artículo pero por motivos diferentes, constituyendo eso también una discrepancia entre ambos que deberá ser resuelta. Sin una adecuada organización de los criterios de exclusión, es probable que se produzcan muchas discrepancias innecesarias.
Los estudios pueden presentar más de un criterio de exclusión, sin embargo, con la simple presencia de uno de ellos ya deberán ser excluidos, sin necesidad de reportar todos los que presentaban. Esto hace que el orden en que se evalúan dichos criterios de exclusión importe y es el motivo por el cual es necesario organizar los mismos antes de comenzar el cribado a texto completo.
La forma de proceder que considero más óptima para organizar los criterios de exclusión es seguir el orden en que suele presentarse la información en un estudio de investigación, es decir, empezar por los criterios de exclusión sobre el diseño del estudio y terminar por aquellos que tengan que ver con las variables resultado o las intervenciones. El orden en que suele presentarse la información en una investigación en términos generales (siempre hay excepciones) sería:
- Diseño del estudio.
- Sujetos.
- Tamaño muestral.
- Intervenciones.
- Variables resultado.
- Análisis estadístico.
Además del orden, debemos simplificar los criterios de exclusión para la elaboración de dicho listado, de manera que queden redactados tal cual aparecerán posteriormente en el diagrama de flujo de la publicación definitiva. Un ejemplo podría ser el siguiente:
- Diseño de estudio inadecuado.
- Sujetos con otras patologías.
- Tamaño muestral inferior a 60 sujetos.
- Ausencia de un grupo con ejercicio terapéutico.
- Ausencia de medidas de resultado de discapacidad.
De este modo, primero iremos al apartado de diseño del estudio y si está presente dicho criterio de exclusión, excluiríamos el artículo sin leer el resto del manuscrito, optimizando el tiempo de cribado. Si ambos revisores proceden con el mismo listado, no debería haber discrepancias entre ellos derivadas del orden de evaluación de los criterios de exclusión.
Cribado de texto completo
Esta sería la última fase (incluyendo la resolución de conflictos de texto completo) de la fase de cribado de una revisión sistemática. A diferencia del cribado de título y resumen, en el que Rayyan puede facilitarnos la tarea, el cribado de texto completo personalmente recomiendo realizarlo mediante Microsoft Excel, ya que creo se optimiza más el tiempo.
El primer paso a realizar en la planificación del cribado a texto completo es organizar los resultados obtenidos del cribado de título y resumen. Mediante Rayyan deberemos exportar dos documentos .csv (valores separados por comas), uno que incluirá los artículos incluidos por ambos revisores y otro que incluirá los artículos incluidos por el tercer revisor en la fase de resolución de discrepancias. Estos dos archivos .csv deberemos unificarlos en uno solo. Una vez exportados los artículos, debemos convertir el archivo .csv al formato de Microsoft Excel. Visualmente, los datos exportados de los artículos incluidos en formato .csv quedarían como:
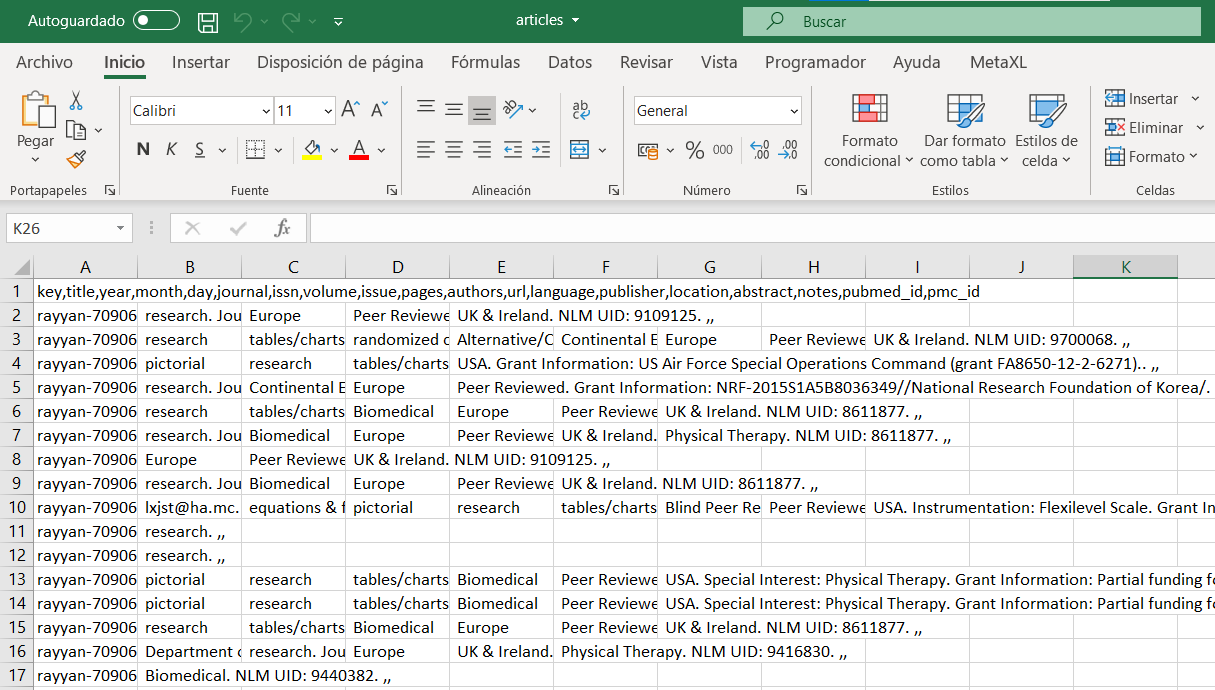
Como puede apreciarse, todos los datos están guardados en una misma celda, separándose con comas cada apartado de los datos (número Rayyan, título, año de publicación…). Para convertir los datos a formato Excel y que cada columna se corresponda con un apartado se debe proceder de la siguiente manera:
- Seleccionar la primera columna.
- Ir a la sección «Datos».
- Abrir la herramienta «Texto en columnas».
- Seleccionar el tipo de archivo «Delimitados».
- Seleccionar el separador «Coma».
- Seleccionar el formato de datos «General».
- Clicar en «Finalizar» y cuando nos pregunte «Aquí hay datos. ¿Desea reemplazarlos?» clicar en «Aceptar».


De este modo ya dispondremos de los datos de los artículos incluidos separados por columnas. Antes de proseguir con la modificación del Excel, deberán encontrarse los documentos a texto completo de todos los estudios incluidos. Mi recomendación a la hora de guardar dichos archivos, es adjudicarles nombre con la siguiente estructura, «Año de publicación. Título del estudio», por ejemplo, «2009. Motion of the Shoulder Complex During Multiplanar Humeral Elevation». El motivo de nombrar así los documentos es simplemente para facilitar su localización mientras se realiza el cribado en el Excel. Si se orden los documentos alfabéticamente en la carpeta donde los guardemos y se hace lo mismo con las filas en Excel, será mucho más fácil encontrar el PDF asociado a cada artículo a cribar en el Excel.
Los únicos datos que serán necesarios en el Excel (el archivo .csv deberá guardarse finalmente como .xlsx que es el formato de Excel) que se utilizará para el cribado de texto completo son por tanto el año de publicación y el título, el resto de columnas deberán ser eliminadas para facilitar la funcionalidad del Excel. Personalmente recomiendo dejar la primera columna con los años de publicación y la segunda con el título de los estudios, es decir, intercambiar el orden en que aparecen al exportar los datos desde Rayyan.
El siguiente paso es construir el sistema de cribado en Excel mediante la elaboración de listas de datos. Primero debemos crear una nueva hoja en nuestro documento de Excel, donde se encontrarán las distintas opciones de nuestras listas. Mi recomendación es crear dos listas, una para la decisión de incluir o no el estudio y otra con los motivos de exclusión:

El motivo de crear estas listas escritas es porque, cuando creemos las listas desplegables a utilizar para el cribado a texto completo, debemos especificar de que celdas debe coger el desplegable las opciones a enseñar. Estas listas desplegables se crean de la siguiente manera:
- Seleccionar todas las celdas en las que vayamos a querer insertar el desplegable.
- En la sección «Datos», seleccionar la herramienta de «Validación de datos», justo a la derecha de «Texto en columnas».
- En «Criterio de validación» seleccionar «Lista» en la sección de «Permitir».
- En esa misma página, seleccionar en la sección «Origen» las celdas donde hemos creado nuestras opciones para dicha lista.
- Clicar en «Aceptar».

Una vez realizados estos pasos, ya dispondremos de celdas con un listado desplegable de opciones, facilitando la tarea a los revisores que se encarguen de realizar la fase de cribado a texto completo.
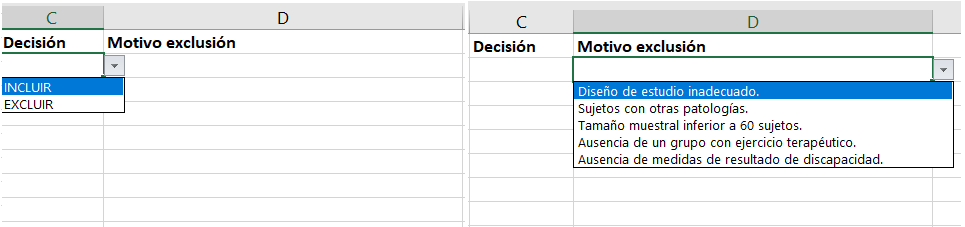
Con todo ello, ya estaría finalizado el Excel para realizar la fase de cribado de texto completo. Para proceder con esta fase, cada revisor cribará los estudios en un Excel independiente. Una vez finalizado el cribado, el investigador principal deberá detectar las discrepancias entre ambos revisores, para lo cual recomiendo unificar las columnas de «Decisiones» de ambos revisores en un mismo Excel. Los estudios en los cuales haya discrepancias deberán enviarse en un nuevo Excel, sin contener ninguna información sobre las decisiones de los revisores previos, a un tercer revisor que será el encargado de resolver las mismas, finalizando de este modo la fase de cribado de la revisión sistemática.
Conclusiones
La fase de cribado es una de las más importantes de una revisión sistemática. Esta fase requiere tener en cuenta algunos aspectos metodológicos importantes para mejorar la calidad de la misma (destacando las partes no explícitas de los criterios de inclusión y exclusión, así como el pilotaje previo) y para optimizar su tiempo de realización (destacando el uso de distintas aplicaciones). Las recomendaciones aquí mencionadas recogen mi forma de trabajar a la hora de planificar y realizar una revisión sistemática, aunque existen otras opciones para ello. Personalmente, animo encarecidamente a todo aquel/aquella que vaya a realizar una revisión sistemática, a estudiar antes detenidamente las consideraciones metodológicas de este tipo de estudios.

Asunciones: Normalidad En esta entrada se recoge una breve explicación de la tan aclamada asunción de normalidad, haciendo hincapié en a que …

Análisis de la "normalidad": Gráficos QQ y PP En esta entrada se recoge una explicación de los gráficos QQ y PP, útiles …

Interpretación de la relevancia clínica: El mal uso de la mínima diferencia clínicamente relevante (I) En esta entrada se proporciona una breve …

Calculadora Muestral: Ensayos Aleatorizados (diferencia ajustada ancova – precisión) En esta entrada se recoge una breve guía práctica de recomendaciones para calcular …
5 respuestas a «Guía Básica de Cribado para Revisiones Sistemáticas»
Muy interesante la entrada.
Soy un defensor de la investigación traslacional (que tenga una utilidad en la práctica clínica), sobre todo para evitar desarrollar investigaciones impecables en la metodología pero con poca utilidad para la intervención en fisioterapia.
Y sin embargo, me doy cuenta de que se puede caer en una simplificación inaceptable de la investigación si no se vigilan los procedimientos.
Recojo las propuestas del software de cribado y las emplearé en mi tesis doctoral para desarrollar el rigor científico requerido.
Gracias por tu comentario Juan!
Muchas gracias por esta interesantísima guía básica sobre la fase de cribado o selección en el proceso de una revisión sistemática.
Saludos cordiales,
María
Gracias a ti María por interesarte en esta entrada, espero que te haya sido útil.
Un saludo!
Me gusta tu porpuesta. Gracias