Asunciones: Normalidad
En esta entrada se recoge una breve explicación de la tan aclamada asunción de normalidad, haciendo hincapié en a que se refiere realmente dicha asunción, si es o no relevante, que implicaciones tiene su incumplimiento y como "evaluarla" y tomar decisiones en investigación para el análisis de datos.
Dentro de los análisis clásicos paramétricos para variables cuantitativas que asumiremos continuas, tales como una t-Student, un Análisis de la Varianza (ANOVA) o covarianza (ANCOVA), o lo que es lo mismo, el modelo de mínimos cuadrados ordinarios o el modelo generalizado de mínimos cuadrados ordinarios, asumimos una serie de consideraciones. Una de estas asunciones es la tan conocida «asunción de normalidad».
A pesar de que la gran mayoría de personas relacionadas con el ámbito de la investigación conocen ese término, actualmente existe mucho mal entendimiento acerca de a que se refiere dicha asunción, como evaluarla y que implicaciones puede tener o no su cumplimiento/incumplimiento.
Entendiendo la asunción de normalidad
La asunción de normalidad implica asumir una distribución normal de los residuos del modelo estadístico que se está implementando, o del estadístico del análisis (ej. distribución de la media muestral). Sin embargo, y esto es algo muy importante, no hace referencia a la distribución de los datos de la muestra, ni tampoco a la distribución poblacional de la variable en cuestión.
Vamos a empezar con el caso de un solo grupo con una sola variable, donde queremos estimar el intervalo de confianza de la media muestral. En esta situación, una práctica habitual es analizar si la distribución de dichos datos se aproxima a la normalidad. El razonamiento que se sigue es que, si los datos se aproximan a la normalidad, entonces es plausible asumir que la distribución muestral de la media también. Aunque este razonamiento tiene cierto sentido, no se cumple a la perfección. Es decir, puede ser que la distribución de los datos de nuestra muestra se aproxime a la normalidad y la de la media muestral no o viceversa. Por ejemplo, puede darse la situación de que tengamos una distribución poblacional ligeramente sesgada a la derecha, que derive en una distribución muestral (n = 200) igual de sesgada. A veces en esta situación, la distribución de la media muestral (con n = 200) se aproxima a la distribución normal, indicando el «cumplimiento» de dicha asunción. Aún así, como comentaré más adelante, que dicha asunción pueda ser plausible tampoco es indicativo de que usar tests paramétricos, o basarnos en la media, sea la mejor opción. En este caso concreto, si la muestra esta sesgada, la media no sería el estimador más apropiado de tendencia central, a expensas de la asunción de normalidad.
Con respecto a los residuos, un ejemplo erróneo del análisis de la asunción de normalidad para un ensayo aleatorizado, sería evaluar la distribución de los datos de la muestra para cada grupo de tratamiento y cada momento de medición por separado. Mientras que, el procedimiento adecuado, sería evaluar la normalidad de los residuos del modelo generalizado de mínimos cuadrados ordinarios implementado para analizar esos datos. Basarse en las distribuciones iniciales de los datos podría llevar al investigador a creer que ese modelo generalizado de mínimos cuadrados ordinarios no es apropiado, usando otros análisis que a lo mejor no son más apropiados y pueden tener otros problemas asociados. El motivo por el que se debe analizar esa distribución de los residuos, es porque los errores estándar calculados para, por ejemplo, una diferencia media ajustada entre dos tratamientos, se calculan con dichos residuos, asumiéndose que siguen una distribución normal en algunos análisis.
Analizando la distribución de los datos
La asunción de normalidad se evaluará siempre de los residuos del modelo estadístico a implementar, ya que no podemos evaluar la distribución del estadístico muestral bajo análisis. Existen distintas maneras de evaluar dicha asunción, que ordenadas de mayor utilidad/adecuación a menor serían:
- Conocer la «naturaleza» de la variable en cuestión.
- Histogramas y gráficos de densidad con outliers.
- Gráficos QQ y PP.
- Medidas de curtosis y asimetría.
- Shapiro-Wilk y Kolmogorov-Smirnov con la corrección de Lilliefors (NO RECOMENDADOS).
En general, solamente con los puntos segundo y tercero, que consisten en la observación visual de cuatro gráficos, se obtiene la información necesaria y de mayor utilidad para discernir si parece cumplirse o no la asunción de normalidad y en que sentido es distinta la distribución de los residuos (si es más plana, si es asimétrica a la derecha, etc). En otra entrada previa recojo una explicación detallada de los gráficos QQ y PP, que podéis leer haciendo click en el enlace de más arriba, donde también explico brevemente porque los tests de contraste no están recomendados para evaluar la asunción de normalidad.
Las medidas de curtosis y asimetría pueden ser de utilidad, siempre que no se utilicen con una interpretación dicotómica con puntos de corte, ya que ello podría llevar a una malinterpretación y toma de decisiones errónea en la práctica de investigación. No es el objetivo de esta entrada explicar la matemática de los mismos, que me guardo para otra ocasión, de modo que simplemente daré una explicación sencilla de su interpretación.
El coeficiente de curtosis de Fisher nos indicaría como de «achatada» está la distribución de los residuos. El valor de curtosis de la distribución normal es de 3, por ello, normalmente al valor del coeficiente se le resta 3 para centrarlo al cero de cara a su interpretación (*Nota: algunas funciones de R y otros paquetes estadísticos te devuelven el valor original del coeficiente de curtosis, sin restarle 3, esto debe tenerse en cuenta a la hora de interpretar el mismo). Este coeficiente puede tomar los siguientes valores:
- Curtosis < 0: Distribución más «plana» que la normal, también llamada platicúrtica.
- Curtosis = 0: Curtosis de la distribución normal, también llamada mesocúrtica.
- Curtosis > 0: Distribución más «puntiaguda» que la normal, también llamada leptocúrtica.
Por su parte, el coeficiente de asimetría de Fisher-Pearson nos informa del grado de asimetría y la dirección de la misma en la distribución de los residuos. Algunos paquetes estadísticos utilizan una formula que aplica una corrección en función del tamaño muestral. Los valores que puede tomar el estadístico son:
- Asimetría < 0: Distribución asimétrica hacia la izquierda.
- Asimetría = 0: Distribución simétrica, como la distribución normal.
- Asimetría > 0: Distribución asimétrica hacia la derecha.
De cara a su interpretación, no daré ningún punto de corte ya que como he comentado, traen más problemas que soluciones. Cuanto más se alejen los valores de los de la distribución normal, peor. Sin embargo, no hay una regla definida de «cuanto» han de alejarse uno u otro para decidir usar métodos estadísticos que no asuman una distribución normal de los residuos.
Por último y quizás el punto más importante, es el conocimiento técnico de la variable resultado en cuestión. A expensas de los análisis de normalidad, hay variables con ciertas características que deben tenerse en cuenta, ya que implican que las mismas no deban analizarse con métodos que asumen una distribución normal de los residuos (o del estadístico muestral).
Un ejemplo son los cuestionarios auto-reportados por el paciente, tales como el SPADI, el TSK-11, el PCS, etc. Todas estas variables están acotadas tanto superior (máximo valor 100%), como inferiormente (mínimo valor 0%). Este acotamiento implica directamente que la asunción de normalidad no se cumple, aparte de traer consigo el incumplimiento de otras asunciones de los modelos de mínimos cuadrados ordinarios, como son directamente que la variable resultado no esté acotada, el incumplimiento de la asunción de homocedasticidad, y el incumplimiento de la asunción de linealidad (en el caso de varios modelos lineales). Por tanto, toda variable resultado que sea un cuestionario auto-reportado, sería erróneo analizarlo con una regresión lineal múltiple, siendo adecuada la opción de una regresión beta. Además, tampoco sería del todo apropiado en un ensayo clínico aleatorizado analizar las diferencias en dichas variables con un ANOVA, ANCOVA u otros modelos basados en mínimos cuadrados ordinarios. Sin embargo, estos análisis erróneos son los que se ven en casi todas las investigaciones realizadas con estas variables resultado. A día de hoy, desconocemos las implicaciones que puede estar teniendo analizar mal los datos en casi todas las investigaciones de este campo, pudiendo ser que muchas relaciones encontradas no sean tales, y que otras no encontradas si que existan.
Otro ejemplo serían las variables ordinales. Los métodos de análisis estadístico para variables ordinales suelen ser más «complejos» o mejor dicho, no dan la falsa sensación de ser «fácilmente interpretables». Esto hace que muchos investigadores tiendan a utilizar métodos que asumen que la variable en cuestión es una cuantitativa continua, como un ANOVA, ANCOVA o una regresión lineal múltiple, para analizar una variable resultado ordinal, bajo la premisa de que si presenta muchas categorías puede aproximarse a la distribución normal, o bajo ninguna premisa, simplemente porque sí. Aquí quiero hacer un apunte importante, en mayúsculas y directo: ESTO ES MENTIRA. Toda variable ordinal ha de ser tratada como ordinal siempre, con los métodos de análisis estadístico apropiados, tanto en ensayos clínicos como en estudios observacionales. Utilizar métodos de mínimos cuadrados ordinarios en estos casos puede llevar a grandes errores en la obtención de los resultados y las conclusiones extraídas de una investigación. Mi recomendación es que, cualquier análisis realizado de esta manera errónea, no sea en absoluto tenido en consideración. Algunos ejemplos de análisis adecuados para variables ordinales son el «proportional odds model» o el «continuation ratio model».
Aprendiendo con ejemplos de investigación reales
Para ejemplificar estas diferencias entre las distribuciones de los datos muestrales y las de los residuos de los modelos implementados, voy a utilizar tres ejemplos simulados: uno de un análisis pre-post para un solo grupo, otro de un análisis estilo ANCOVA, con una medición basal y una post-tratamiento con dos grupos a comparar, y un tercero de una regresión lineal múltiple.
Ejemplo 1: Diferencia intra-grupo
Para este ejemplo he simulado una situación en la que tenemos una distribución poblacional de la medición basal y la post-tratamiento que no es normal, con una asimetría izquierda notoria. El objetivo de este estudio es analizar el cambio de la situación basal a la post-tratamiento para un solo grupo. Los análisis de la normalidad de los datos muestrales serían los siguientes:
- Medición basal:
- Shapiro-Wilk: p = 0.00143
- Asimetría: -1.10
- Curtosis: 0.35
- Medición post-tratamiento:
- Shapiro-Wilk: p = 0.01347
- Asimetría: -0.84
- Curtosis: -0.19
Los gráficos Q-Q para la medición basal y la post-tratamiento serían los siguientes:

Basándonos en dichos análisis de la distribución de los datos, un investigador podría decidir que no parece ser plausible la asunción de normalidad y decantarse por usar tests no paramétricos (no recomendados) u otras opciones de análisis robustos (recomendadas) sin necesidad.
Veamos ahora que pasa si nos centramos en los residuos del modelo estadístico a implementar, que es en los que se aplicaría en mayor medida la asunción de normalidad. En el caso de un solo grupo y dos mediciones, dichos residuos son la dispersión de la variable diferencia (post – basal). Para evaluar su distribución podemos calcular dicha diferencia para cada individuo y en esa nueva variable aplicar los distintos métodos de análisis de la asunción de normalidad. En este caso tendríamos los siguientes datos:
- Variable diferencia:
- Shapiro-Wilk: p = 0.9527
- Asimetría: -0.08
- Curtosis: 0.0006
El gráfico QQ para dicha variable diferencia sería el siguiente:
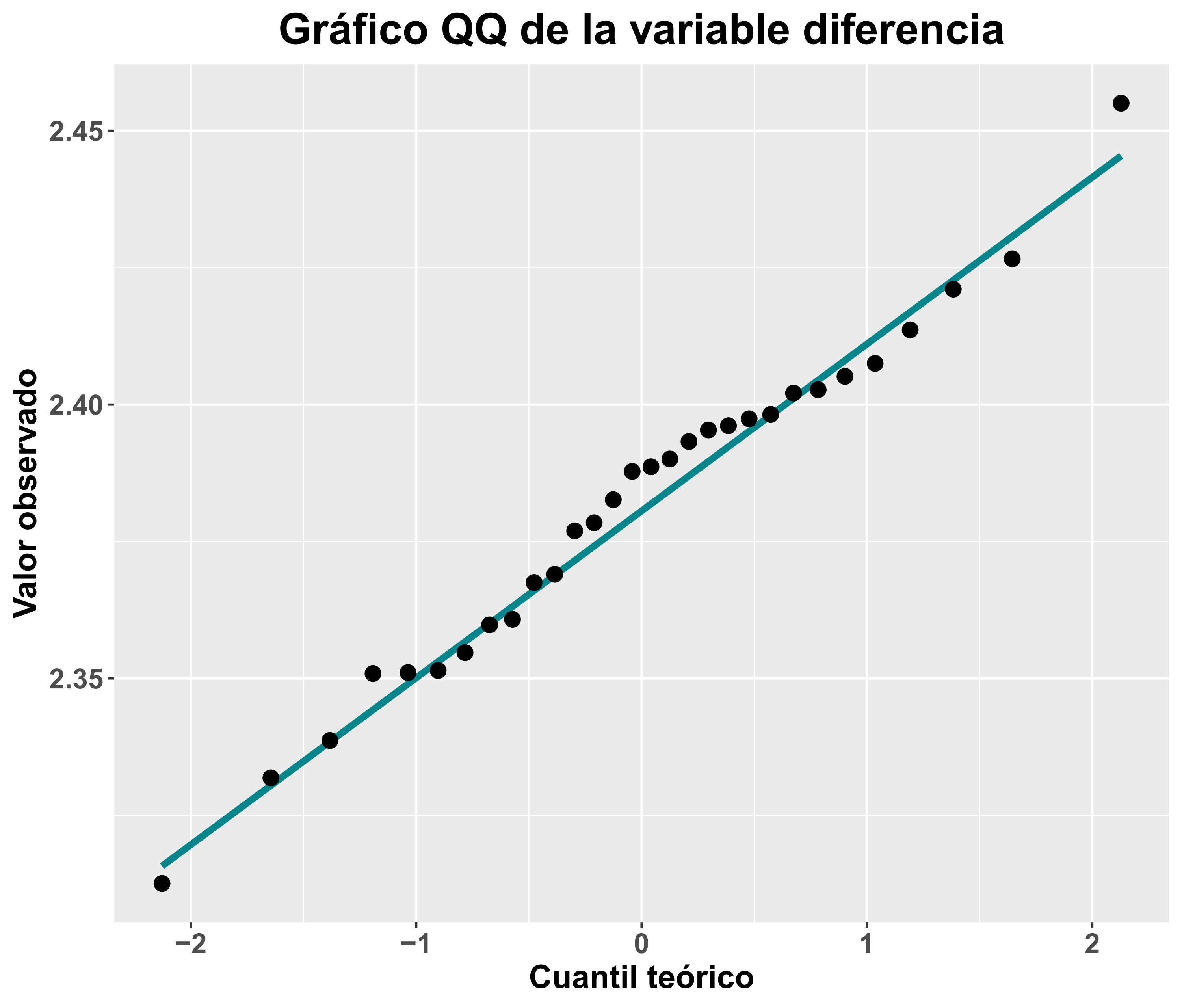
En este caso, las conclusiones que podríamos sacar son muy distintas a las de los análisis iniciales, pareciendo bastante plausible el cumplimiento de la asunción de la normalidad y pudiendo analizarse los datos con una prueba basada en mínimos cuadrados ordinarios.
Ejemplo 2: Modelo estilo ANCOVA
El segundo ejemplo es algo más aproximado a lo que puede ser la situación de un ensayo clínico aleatorizado real. En este ejemplo he simulado datos, también con una distribución poblacional sesgada a la izquierda, para dos grupos en dos momentos, uno antes del tratamiento (medición basal) y otro tras el tratamiento (medición post-tratamiento). Por tanto, tenemos un total de cuatro mediciones. Siguiendo el procedimiento erróneo de evaluar la normalidad de los datos muestrales, se obtienen los siguientes estadísticos:
- Medición basal grupo 1:
- Shapiro-Wilk: p = 0.00143
- Asimetría: -1.10
- Curtosis: 0.35
- Medición basal grupo 2:
- Shapiro-Wilk: p < 0.001
- Asimetría: -2.07
- Curtosis: 5.14
- Medición post-tratamiento grupo 1:
- Shapiro-Wilk: p = 0.00724
- Asimetría: -0.86
- Curtosis: -0.18
- Medición post-tratamiento grupo 2:
- Shapiro-Wilk: p < 0.001
- Asimetría: -2.01
- Curtosis: 4.97
El modelo de mínimos cuadrados ordinarios que se utilizaría para analizar este estudio sería una regresión lineal de la siguiente manera:
Post-tratamiento = Constante + b1*Basal + b2*Grupo + e
Donde «e» son los residuos del modelo. Implementando dicho análisis de regresión, para obtener diferencias entre-grupos «ajustadas» para la medición basal, podemos extraer los residuos del mismo y llevar a cabo los análisis de la asunción de normalidad en estos. Los resultados serían:
- Residuos del modelo de mínimos cuadrados ordinarios:
- Shapiro-Wilk: p = 0.4745
- Asimetría: 0.25
- Curtosis: -0.23
Nuevamente, el análisis de los residuos nos orienta a tomar una decisión muy diferente a los análisis de normalidad realizados de la manera equivocada sobre la distribución de los datos muestrales.
Ejemplo 3: Regresión lineal múltiple
Otra práctica habitual en investigación es analizar la distribución de todas las variables cuantitativas que se han medido, a la hora de realizar un análisis de regresión lineal múltiple. Este procedimiento también sería erróneo. La asunción de normalidad, como se ha comentado, hace referencia a los residuos de dicho modelo de regresión. Estos residuos serían la «parte» que no podemos predecir de cada individuo de la muestra en la variable resultado de interés (ej. fuerza) en función de los predictores incluidos en el modelo (ej. edad, estatura, peso y sexo). Por tanto, todo lo que tiene que ver con la asunción de normalidad en estos modelos, se relaciona únicamente con la variable resultado (fuerza), pero no es necesario para realizar un modelo de mínimos cuadrados ordinarios que las variables predictoras tengan una distribución normal. De ser así, no sería posible incluir ningún predictor categórico, pues estos nunca van a seguir una distribución normal.
La importancia (o no) de la normalidad y la toma de decisiones
Aunque la asunción de la normalidad es una de de las más conocidas por investigadores, no es la «más importante». Muchos métodos basados en mínimos cuadrados ordinarios «funcionan» más o menos bien ante pequeñas desviaciones de dicha asunción, siempre que se cumplan otras asunciones más importantes como la de homocedasticidad. Curiosamente, el resto de asunciones de los modelos de mínimos cuadrados ordinarios no suelen ser tan conocidas, habiendo pocos estudios que analicen adecuadamente la homocedasticidad de los residuos con sus adecuadas estratificaciones pertinentes, o evalúen si quiera otras asunciones como la de linealidad o aditividad (según el modelo implementado). Por eso, aunque a veces existan pequeñas desviaciones, en función de como sean estas y otros aspectos, podemos seguir implementando esos modelos.
Por otro lado, aunque los «análisis de normalidad» salgan favorables para dicha asunción, es erróneo también tomar decisiones solo basándonos en ello. Podemos tener una situación en la que la distribución de los datos (SI, habéis leído bien, LOS DATOS) esté sesgada a la derecha. En este caso, aunque se parezca cumplir la asunción de normalidad de los residuos, puede que debamos considerar que predecir la media (que es lo que predecimos con un modelo de mínimos cuadrados ordinarios) no sea lo más apropiado, ya que no sería un buen estimador de tendencia central, pudiendo ser más oportuno, por ejemplo, utilizar otros modelos de regresión que se basan en la predicción de la mediana.
Dicho de otra manera, la toma de decisiones en investigación de cara a la realización de análisis estadísticos es compleja y no podemos simplificarla, ni a puntos de corte arbitrarios ni a una interpretación aislada de uno, dos o varios análisis. Hay que tener en cuenta el conjunto de información disponible, tanto técnica como a nivel estadístico, para decidir cual es la mejor opción para una situación concreta de investigación.
Conclusión
La asunción de normalidad no hace referencia a la distribución de los datos de la muestra, se refiere a la distribución de lo residuos del modelo estadístico implementado o de la distribución muestral del estadístico bajo análisis. Existen diversas formas de evaluar dicha asunción, siendo algunas más apropiadas que otras. No obstante, debemos siempre tener en cuenta que hay que tener en cuenta otros aspectos para decidir como analizar los datos, ya que la asunción de normalidad no es lo más relevante en esa toma de decisiones en investigación.

Asunciones: Normalidad En esta entrada se recoge una breve explicación de la tan aclamada asunción de normalidad, haciendo hincapié en a que …

Análisis de la "normalidad": Gráficos QQ y PP En esta entrada se recoge una explicación de los gráficos QQ y PP, útiles …

Interpretación de la relevancia clínica: El mal uso de la mínima diferencia clínicamente relevante (I) En esta entrada se proporciona una breve …

Calculadora Muestral: Ensayos Aleatorizados (diferencia ajustada ancova – precisión) En esta entrada se recoge una breve guía práctica de recomendaciones para calcular …