
Interpretación de medias: El mal uso de la Mínima Diferencia Detectable
En esta entrada profundizo en la estadística subyacente a la utilización de la mínima diferencia detectable (MDD) en la interpretación de diferencias medias, que actualmente se sigue haciendo en diversas publicaciones del campo de la Fisioterapia. A lo largo de la entrada, explicaré los motivos por los cuales pienso esta práctica está equivocada y puede llevarnos a fallos cruciales de interpretación de los resultados de una investigación.
Nota: En esta entrada se utilizan conceptos avanzados de estadística aplicada y puede que, sin una base previa, resulte más complicada su comprensión. No se abordarán múltiples aspectos básicos para no extender demasiado el contenido de la misma, dándose por hecho que el lector presenta esa base de conocimiento.
La mínima diferencia detectable (MDD) es un estadístico comúnmente reportado en los análisis de fiabilidad con variables continuas. Este estadístico constituye un limite de un intervalo de confianza (IC), normalmente del intervalo al 90% o 95% de confianza (utilizaré este último para todas las explicaciones y simulaciones a lo largo de la entrada). Su interpretación simplista sería la siguiente.
Imaginemos que tenemos un sujeto al que hemos medido la fuerza isométrica máxima de rotación externa de hombro, con un dinamómetro manual. En la primera medición antes de comenzar el tratamiento, el sujeto muestra una fuerza de 130N, mientras que en la segunda medición tras la aplicación del tratamiento, el sujeto muestra un valor de fuerza de 135N. Sabemos que la fiabilidad del dinamómetro no es perfecta, es decir, que al utilizar este instrumento dentro del procedimiento empleado, cometemos errores en la medición. Entonces, ¿Cómo podríamos saber si la diferencia observada en el post-tratamiento no se ha debido a un error de medición? Aquí es donde entra en juego el concepto de MDD.
La mínima diferencia detectable al 95% de confianza (MDD95%), es un valor que, partiendo de que se cumplen distintas asunciones y que lo único que ha influido en la diferencia observada es el error de medición (es decir, que no hay ningún otro factor, ni la intervención, que hayan influido), por encima del mismo solo se encontrarían un 5% de las posibles diferencias absolutas obtenibles debidas al error de medición. De forma que se asume que, si obtenemos una diferencia superior a dicho valor, como es «poco plausible» obtener esa diferencia bajo la hipótesis de que dicha diferencia se haya obtenido solo por un error de medición, entonces rechazamos dicha hipótesis.*
*Nota: Debemos tomar está definición como muy simplista y «con pinzas», ya que realmente no es tan sencilla su interpretación en términos de probabilidad, pero no entraré en ese detalle en esta entrada, pues no es su propósito.
En términos más formales, si medimos a un sujeto infinitas veces y asumimos que lo único que influye en las diferencias observadas entre las distintas mediciones es el error proveniente del procedimiento de medición empleado y calculamos diferencias de parejas de mediciones de manera aleatoria, el intervalo de confianza al 95% de esa distribución de datos (de esas diferencias entre dos mediciones seleccionadas de manera aleatoria), es decir, más o menos los valores que se alejan 1.96 desviaciones estándar (DEd) asumiendo algunas cosas, eso sería el valor de la MDD95%. La fórmula que suele utilizarse para el cálculo de la MDD95% es la siguiente:
$$MDD95\% = 1.96*DE_d = 1.96*EEM*\sqrt 2$$
En esta fórmula el EEM es el error estándar de la media, que es una estimación de la desviación estándar resultante de medir a un sujeto infinitas veces influyendo solo el error de medición. Como en la MDD95% tenemos dos mediciones y no solo una, se multiplica el EEM por la raíz cuadrada de dos, debido a que:
$$EEM = \frac{DE_d}{\sqrt 2}$$
$$DE_d = EEM*\sqrt 2$$
Después de esta introducción, vamos a focalizarnos en el tema concreto de esta entrada. Como he comentado, la MDD95%es un estadístico orientado a interpretar la diferencia entre dos mediciones realizadas a un mismo sujeto. Sin embargo, la MDD95% se utiliza a veces también para interpretar diferencias de medias muestrales y para cálculos de tamaño muestral, dos procedimientos a mi parecer erróneos por los motivos que expondré a continuación.
Mínima diferencia detectable en la interpretación de diferencias medias
Mostraré primero las consecuencias de utilizar la MDD95% en la interpretación de la diferencia media entre dos grupos. Voy a simular un estudio en el que queremos comparar la fuerza isométrica máxima de rotación externa de hombro, medida con dinamometría, entre sujetos con y sin tendinopatía del manguito rotador. Asumiremos los siguientes valores poblacionales reales y los siguientes valores de error de medición (mismo error de medición en ambas poblaciones):
$$Tendinopatía = \{\mu_t = 140, \sigma_t = 10\}$$
$$Sanos = \{\mu_s = 145, \sigma_s = 10\}$$
$$Error \ de \ medicion = \{EEM = 3.61, MDC95\% = 10\}$$
Partiendo de estos datos, si asumimos un umbral crítico de significación de p < .05, necesitaríamos 64 sujetos de cada grupo para conseguir una potencia estadística del 80%, asumiendo que no se cometen errores en el proceso de medición. Si asumimos el error de medición mencionado anteriormente la potencia disminuye y si, además de eso, utilizamos el punto de corte de la MDD95% para decidir cuando hay diferencias entre los grupos y cuando no, la potencia disminuye aun más, quedando las tres definidas para esa misma muestra como:
- Sin error de medición: 80%.
- Con error de medición: 75%.
- Con error de medición + MDC95%: 0.40% (aproximada). *Esta potencia se ha calculado asumiendo que hay diferencias reales si y solo si el resultado obtenido es estadísticamente significativo y además, superior a 10N, el valor de la MDC95%.
Como puede apreciarse, al utilizar la MDD95% como punto de corte para decidir si «hay diferencias reales o no» entre estas dos poblaciones, la potencia estadística disminuye notoriamente. Además, debemos tener en cuenta otro factor, una paradoja que se da debido a la relación entre el tamaño muestral y la distribución de las diferencias medias.
Según incrementamos el tamaño muestral, la estimación de la diferencia media es más precisa, es decir, los valores de diferencias medias observados se aproximarán cada vez más al valor real, en este caso de 5N. No obstante, aunque se incremente el tamaño muestral, el valor de la MDD95% no varía, es fijo. Por tanto, aunque de manera habitual incrementar el tamaño muestral incrementa la potencia, en este caso sucede lo contrario. Al aproximarse cada vez más los valores a 5N, habrá menos cantidad de muestras en las que la diferencia observada sea superior a 10, de manera que la potencia disminuye. Por ejemplo, para los siguientes tamaños muestrales, la potencia aproximada sería:
- 75 sujetos por grupo = 0.25%
- 80 sujetos por grupo = 0.18%
- 90 sujetos por grupo = 0.07%
- 100 sujetos por grupo = 0.04%
Es decir, no podríamos mejorar la potencia estadística incrementando el tamaño muestral, si no que tendríamos que disminuirlo, algo que carece de sentido. Este efecto dependerá del efecto real bajo estudio (la diferencia de medias real) y la fiabilidad del procedimiento de medición. A medida que la fiabilidad se aproxime a una fiabilidad perfecta (es decir, la MDD95% tienda a cero), el efecto negativo de usar la MDD95% será menor. Sin embargo, puede observarse como en casos como el presente, con una fiabilidad muy buena con un EEM de tan solo 3.61, el efecto del uso de la MDD95% es devastador.
Mínima diferencia detectable en el cálculo del tamaño muestral
Otra práctica que he podido observar algunas veces en la investigación en Fisioterapia, es la utilización de la MDD95% para los cálculos de tamaño muestral, donde se produce también otra situación paradójica similar a la descrita anteriormente.
Como ya he comentado, según incrementa el error de medición disminuye la potencia estadística, por ejemplo para el caso anterior con 64 sujetos por grupo, la potencia estimada para los siguientes errores estándar de la media sería:
- EEM de 5 = 71%.
- EEM de 7 = 63%.
- EEM de 10 = 51%.
- EEM de 15 = 34%.
Esto hace que, según aumente el error de medición, debamos incrementar el tamaño muestral si queremos mantener una potencia estadística deseada (por ejemplo, del 80%). Asumiendo los valores anteriores de EEM, la muestra necesaria para alcanzar un 80% de potencia sería:
- EEM de 0 = 64 sujetos por grupo.
- EEM de 5 = 80 sujetos por grupo.
- EEM de 7 = 95 sujetos por grupo.
- EEM de 10 = 127 sujetos por grupo.
- EEM de 15 = 205 sujetos por grupo.
Ahora procedamos como he visto hacer a algún/a investigador/a de nuestro campo, utilizando el valor de la MDD95% como la diferencia de medias real estimada a detectar en nuestro estudio. Vamos a asumir que la dispersión de la diferencia está fija en 10 (aunque luego explicaré que esto no es así), de manera que para distintos valores de MDD95% usados como estimadores de la «diferencia de medias real», el tamaño muestral para un 80% de potencia sería:
- MDD95% de 3 = 176 sujetos por grupo.
- MDD95% de 5 = 64 sujetos por grupo.
- MDD95% de 7 = 33 sujetos por grupo.
- MDD 95% de 10 = 17 sujetos por grupo.
Es decir, según incrementamos la diferencia de medias real estimada, el número de sujetos necesario para alcanzar un 80% de potencia (manteniendo el resto constante) disminuye. Es aquí donde se da la paradoja. Al inicio he comentado que, a menor fiabilidad hay más variabilidad de error y por tanto, la potencia estadística disminuye y necesitamos más muestra para alcanzar la potencia deseada. A menor fiabilidad, mayor es el valor de la MDD95%. Por tanto, ¿Cómo vamos a usar la MDD95% para calcular el tamaño muestral si su utilización disminuye aún más la muestra necesaria calculada? En efecto, carece de sentido. En los últimos cálculos asumí que la dispersión de las diferencias estaba fijada en 10, sin embargo, esto no es realista, ya que según disminuye la fiabilidad dicha dispersión aumenta.
Asumiendo una dispersión real (sin errores de medición) de 10 en cada muestra, con una diferencia de medias real de 5N y un tamaño muestral de 64 sujetos por grupo, teníamos un 80% de potencia. Ahora mostraré que sucede en la potencia real estimada de un estudio, cuando se incrementa el error de medición (EEM) y se utiliza además para el cálculo del tamaño muestral la MDD95% asociada a ese error de medición:
$$\begin{array} {| ccc |} \hline EEM & Potencia \ real & Muestra \ 80\% & MDD95\% & Muestra \ MDD95\% & Potencia \ real \ MDD95\% \\ \hline 2.53 & 78\% & 68 & 7 & 33 & 49\% \\ \hline 3.61 & 75\% & 72 & 10 & 17 & 26\% \\ \hline 4.33 & 73\% & 76 & 12 & 12 & 19\% \\ \hline \end{array}$$
Como puede apreciarse, el uso de la MDD95% para estimar el tamaño muestral se traduce en una mayor y considerable pérdida de potencia estadística real de nuestro estudio, al disminuir el tamaño muestral cuando en realidad, al haber menos fiabilidad, deberíamos incrementarlo tal y como se muestra en la tercera columna.
Mínima diferencia media detectable
Como he comentado anteriormente, el uso de la MDD95% está orientado a diferencias entre dos mediciones realizadas a un mismo individuo, es decir, es un estadístico orientado a individuos y no a muestras.
Una pregunta que podríamos hacernos es, si podemos calcular la MDD95% para diferencias individuales, ¿podemos también calcularla para diferencias medias? La respuesta es sí, a este valor le llamaré mínima diferencia media detectable al 95% de confianza (MDMD95%). Ahora supongo que, a lo mejor, te estas planeando la siguiente pregunta obvia, ¿podemos usar la MDMD95% para interpretar diferencias medias? Y la respuesta quizás no te resulte tan obvia y no te guste tanto: no.
Si retomamos las fórmulas anteriores:
$$DE_d = EEM*\sqrt 2$$
$$MDD95\% = EEM*\sqrt 2*1.96 = DE_d*1.96$$
La DEd es la desviación estándar de las diferencias individuales entre las dos muestras. Sin embargo, nosotros estamos interesados en la dispersión de la media, no de los valores individuales, de modo que tenemos que usar un estadístico que recoja dicha dispersión de la media, que es el error estándar de la media:
$$EE_{media} = \frac{DE_d}{\sqrt n}$$
Con este error estándar, podemos reescribir la fórmula de la MDD95% para obtener la fórmula de la MDMD95%:
$$MDMD95\% = \frac{MDD95\%}{\sqrt n} = \frac{EEM*\sqrt 2*1.96}{\sqrt n}$$
Siendo n igual al tamaño muestral total entre dos (asumiendo que ambos grupos tienen el mismo tamaño muestral). De este modo, la MDMD95%, a diferencia de la MDD95%, si varía en función del tamaño de la muestra, a mayor tamaño muestral empleado, menor MDMD95%.
Sin embargo, no tiene sentido utilizar la MDMD95% para interpretar diferencias medias, ya que no aporta información útil si ya usamos el punto de corte del umbral crítico de significación (p < .05). La explicación a este fenómeno recae en las varianzas involucradas en sus respectivos cálculos.
Cuando calculamos la MDMD95% solamente estamos teniendo en cuenta el error atribuible a la ausencia de fiabilidad perfecta del procedimiento de medición, es decir, si tenemos dos muestras a comparar, entonces:
$$\sigma^2_{sanos} = \sigma^2_{error_{sanos}}$$
$$\sigma^2_{tendinopatia} = \sigma^2_{error_{tendinopatia}}$$
$$MDMD95\% = \frac{\sqrt {\sigma^2_{error_{sanos}} + \sigma^2_{error_{tendinopatia}}}*1.96}{\sqrt n}$$
Sin embargo, si pensamos ahora en un experimento real, cuando calculamos un valor-p o un intervalo de confianza para una diferencia media entre dos muestras, ahí ya no solo tenemos el error de medición, sino que también tenemos otro error, el proveniente de la variabilidad real de dicha variable en cada una de las muestras (es decir, que los sujetos son distintos entre sí no solo por errores de medición, sino porque efectivamente tienen distinta fuerza), que arriba se ignora en los cálculos:
$$\sigma^2_{sanos} = \sigma^2_{real_{sanos}} + \sigma^2_{error_{sanos}}$$
$$\sigma^2_{tendinopatia} = \sigma^2_{real_{tendinopatia}} + \sigma^2_{error_{tendinopatia}}$$
Con estos datos podemos calcular el intervalo de confianza asociado a una diferencia media entre dos grupos de igual tamaño muestral (no es exactamente la misma que para una t-Student pero sirve igual para ejemplificar este punto de la entrada):
$$IC95\%= \bar x_{dif} \pm \frac{\sqrt {\sigma^2_{real_{sanos}} + \sigma^2_{error_{sanos}} + \sigma^2_{real_{tendinopatia}} + \sigma^2_{error_{tendinopatia}}}*1.96}{\sqrt n}$$
Como se aprecia, en el segundo caso hay más variabilidad, más error en el cálculo. Esto produce la siguiente situación y es que, si una diferencia media es estadísticamente significativa al evaluarla con una prueba t-Student (fórmula similar a la última), entonces dicha diferencia media estará siempre por encima del valor de la MDMD95%, es decir, es imposible obtener una diferencia de medias estadísticamente significativa que sea inferior a la MDMD95% y es por ello que, como comenté al inicio de este apartado, la MDMD95% no aporta más información útil para interpretar la diferencia de medias y por tanto, carece de sentido su utilización.
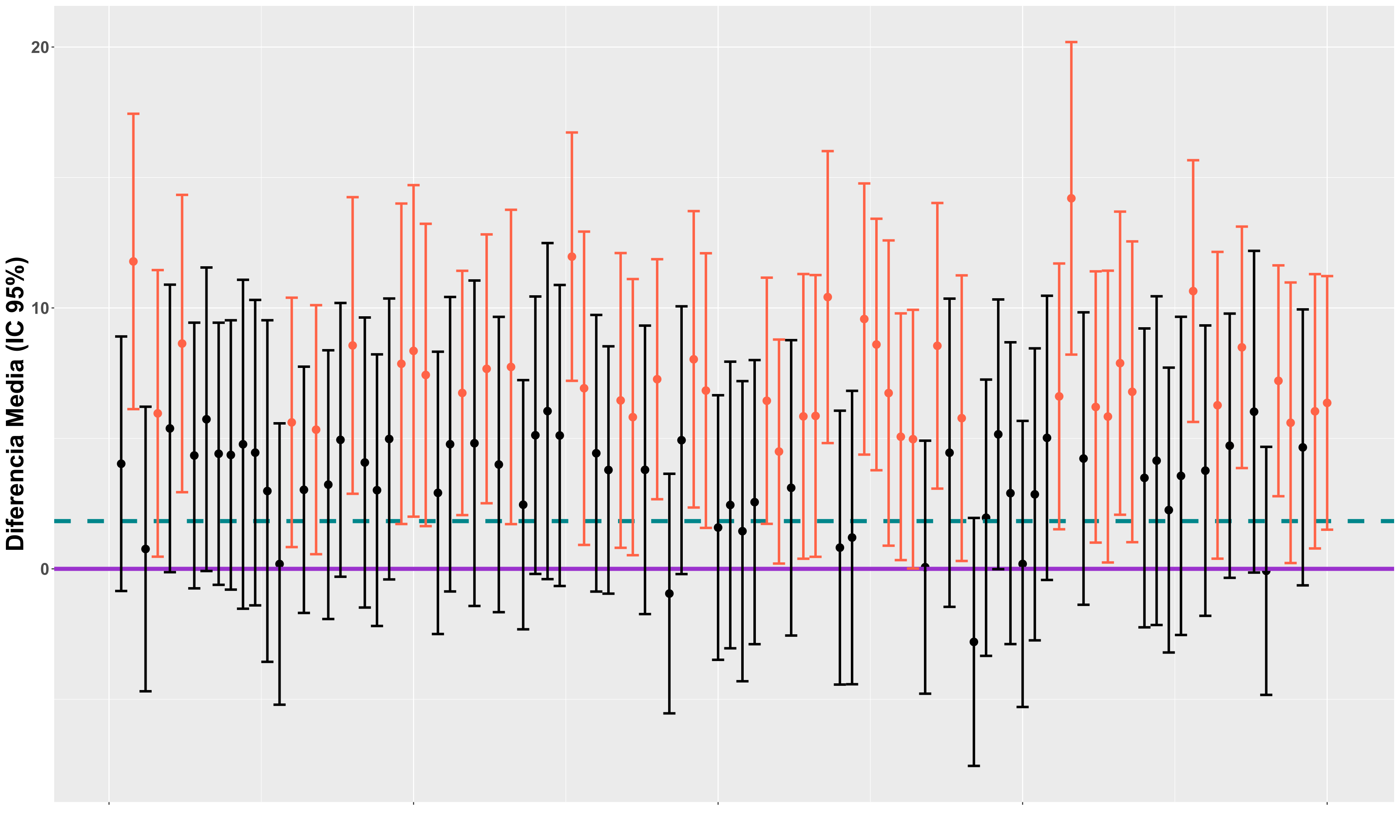
En la figura anterior se reflejan 100 estudios simulados, con 30 sujetos por grupo en cada uno, asumiendo una diferencia media real de 5N, con una desviación estándar en cada grupo de 10 y un EEM de 3.61. En el gráfico se muestra la diferencia media de cada simulación con su respectivo intervalo de confianza al 95% basado en una prueba t-Student. La línea horizontal morada continua marca el cero, de modo que las simulaciones cuyo limite inferior del intervalo de confianza (color tomate) no sobrepasa el cero, son significativas para p < .05. La línea horizontal azul entrecortada marca el valor de la MDMD95% para ese EEM y ese tamaño muestral, que es de 1.83. Como puede apreciarse, ninguno de los resultados significativos (color tomate) presenta una diferencia media por debajo de la MDMD95%, ejemplificando lo comentado anteriormente acerca de que la MDMD95% no aporta información útil adicional.
Conclusiones
La mínima diferencia detectable es un estadístico orientado a interpretar diferencias individuales, pero no muestrales. La utilización de este valor para interpretar diferencias de medias muestrales y/o realizar cálculos de tamaño muestral tiene consecuencias nefastas en la potencia estadística y la adecuada interpretación de los resultados de una investigación. Por su parte, la mínima diferencia media detectable, tampoco debería utilizarse para interpretar las diferencias medias de una investigación, ya que no aporta más información útil que la aportada por el intervalo de confianza calculado para dicha diferencia media.

Asunciones: Normalidad En esta entrada se recoge una breve explicación de la tan aclamada asunción de normalidad, haciendo hincapié en a que …

Análisis de la "normalidad": Gráficos QQ y PP En esta entrada se recoge una explicación de los gráficos QQ y PP, útiles …

Interpretación de la relevancia clínica: El mal uso de la mínima diferencia clínicamente relevante (I) En esta entrada se proporciona una breve …

Calculadora Muestral: Ensayos Aleatorizados (diferencia ajustada ancova – precisión) En esta entrada se recoge una breve guía práctica de recomendaciones para calcular …



