Ejemplo número uno:
Un grupo de investigadores realizan un ensayo aleatorizado con 15 sujetos por grupo, porque eran los que tenían disponibles. Tras ello, obtienen un una diferencia media de 5 puntos (p = 0.011). Sin embargo, como tenían poca muestra, no acaban de estar convencidos de que puedan confiar en esos resultados para rechazar la H0 y aceptar la H1, por ello, deciden calcular la potencia observada del estudio, ya que establecen que si dicha potencia es baja, entonces a lo mejor ese resultado aunque sea significativo, no es una prueba grande en contra de la H0, mientras que si se obtiene una potencia observada alta, eso nos indicaría que podemos confiar más en estos resultados, ya que teníamos muestra suficiente para encontrar dicha diferencia, y por tanto debemos tener más confianza en que podemos rechazar la H0. Realizan el cálculo y obtienen una potencia observada del 73%, concluyendo por tanto que efectivamente, tienen pruebas robustas para rechazar la H0.
Ejemplo número dos:
Otro grupo de investigadores realizan otro ensayo aleatorizado con 15 sujetos por grupo, también porque eran los que tenían disponibles. En este caso, los investigadores obtienen una diferencia media de 2 (p = 0.54). Sin embargo, como tenían poca muestra, deciden calcular la potencia observada, ya que puede ser que ese resultado no sea porque la hipótesis nula es cierta, sino simplemente porque tenían poca potencia para detectar la misma, por el escaso tamaño muestral. De modo que establecen que, si la potencia observada es baja, entonces puede ser simplemente un problema del tamaño muestral, y no de que la H0 sea cierta, y si obtienen una potencia alta, entonces sí que es plausible que los resultados obtenidos se deban a que la H0 es cierta. Obtienen una potencia observada del 9%, concluyendo por tanto que sus resultados posiblemente se deban al pequeño tamaño muestral y no a que la H0 tenga que ser cierta.
Ejemplo número tres: Contraintuitivo
Un tercer grupo de investigadores realizan otro ensayo aleatorizado, en este caso, disponen de 300 sujetos por grupo en su hospital. Obtienen una diferencia media de 1.1 (p = 0.24). Sin embargo, realizan el mismo razonamiento anterior y deciden calcular la potencia observada, resultando en un valor del 22%. Concluyen por tanto que, como la potencia observada es baja, los resultados no se deben en verdad a que la H0 tenga que ser cierta, sino que es un problema de que se tenía poca muestra.
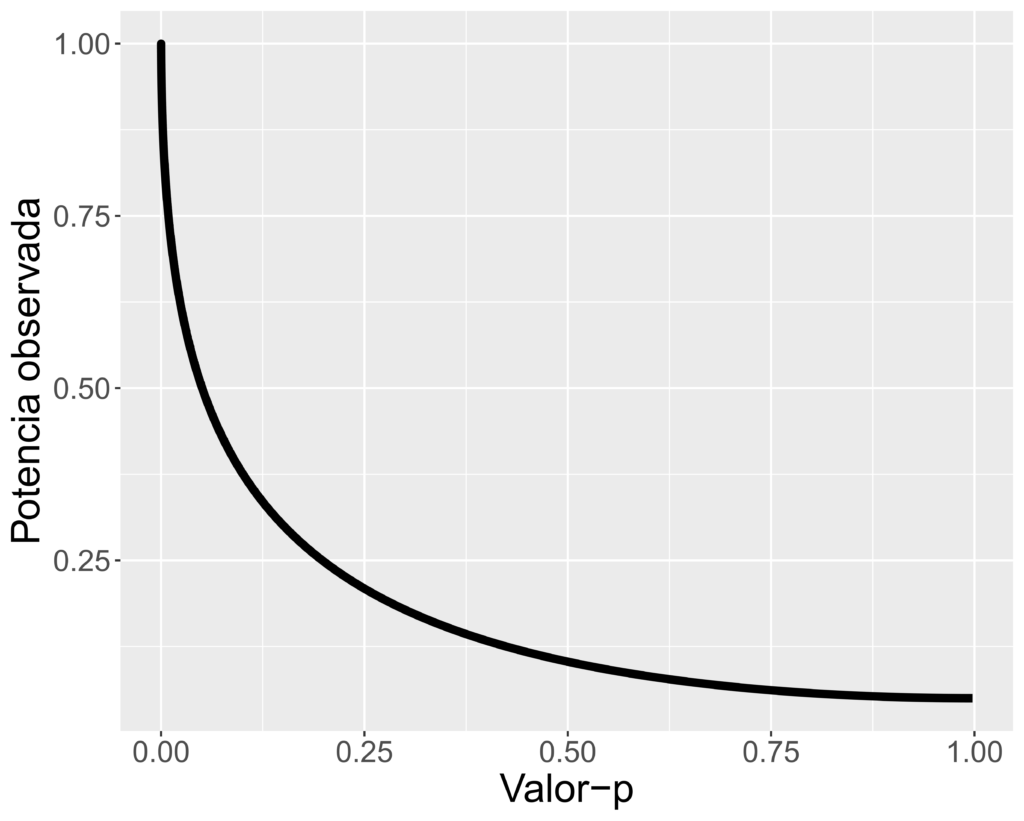
Puede ser que los dos primeros ejemplos pareciesen “razonables”, sin embargo, aplicando ese mismo razonamiento, nos hemos topado con un tercer ejemplo en el que se afirma que una muestra de 300 sujetos por grupo, es también pequeña. De hecho, esto sucedería incluso aunque la muestra hubiera sido de 3000 sujetos por grupo, las conclusiones de dichos investigadores habrían sido las mismas, que la muestra era demasiado pequeña y que dicho valor-p no constituía un indicativo de que la H0 fuese más plausible que la H1.